Jekyll2025-05-02T02:35:54+00:00https://www.ryancompton.net/feed.xmlRyan ComptonRyan Compton personal blog.Ryan Comptonryan@ryancompton.netSurf Bikes!2024-03-03T00:00:00+00:002024-03-03T00:00:00+00:00https://www.ryancompton.net/2024/03/03/surfbikesOn a few occasions I’ve been fortunate enough to live within biking distance of a surf break. One of my favorite activities to do in this situation is outfit a bicycle with a surfboard rack and use it for transportation to the beach.
I got this bicycle for free when I purchased my first mountain bike from someone on Craigslist in Glendale in late 2006. I took both bicycles back to Westwood via bus where I was promptly stopped and questioned by the police as to why I had two bikes with me on the bus. Neither showed up as reported missing so they let me out. The next year I moved to Santa Monica near Wilshire and 17th Street and built this rack so I could ride to Venice Beach to surf in the morning. The ride was long and the waves were bad but I enjoyed every minute of it.
In 2008 I moved too far from the coast for this to be practical so I donated the bicycle to Bikerowave and didn’t put another one together for ~10 years.
Shogun (unknown model) – 2017
When I started working at Google we moved to Santa Cruz and I rode the corp bus into Mountain View every morning. But if I got up early enough I could sneak in a quick session, usually at Steamer Lane, before work via bicycle. This bike, an unknown model built by Shogun, was discarded by one of my neighbors. I fixed it up and slapped an off-the-shelf surfboard rack on it so I could get right up to the cliff and lock it on the fence overlooking the ocean. It lasted almost a year until someone stole it from the carport while I was in the backyard putting my board in the shed.
Trek 800 – 2018
After the Shogun was stolen I picked up this from someone on Craigslist and rode it home in the rain. I opted to build another PVC rack this time as I was unimpressed with the one I bought for the Shogun. When we moved away from Santa Cruz I gave it away.
Univega Alpina Sport – 2020
When we moved to Long Beach I effectively gave up on surfing as the breakwater blocks all the waves and will never go away. Luckily, Belmont Shore is a great place to kiteboard and kite gear is pretty compact. I fit my rig onto the same PVC rack used earlier with some extra stuff on the back. It works, but the huge downside to this is that riding around when the wind is 20kts is not a great activity.
ET Cycles 720 – 2023
Kiteboarding is fun, but it’s quite different from surfing as you’re getting pulled by the wind instead of the waves. I was never able to shake this and eventually found myself back in the waves at Seal Beach. Seal Beach is arguably the best foil wave on the West Coast and I couldn’t be happier about the new sport. It’s a few miles from the building we live in so I was driving there. One night our catalytic converter was stolen and the wait for a replacement was 6+ months. This is how I discovered e-bikes and they are amazing, like riding downhill the whole way. I used an off the shelf rack for this build because the foil gets in the way of the PVC rack I’m familiar with. There’s also a box on the back that holds the mast high to prevent the wing from dragging during a turn.
when I was at KDD 2023 I locked this up outside the Long Beach Convention Center for a day with a powerful Kryptonite lock. But the city apparently doesn’t install strong bike racks and my e-bike was taken.
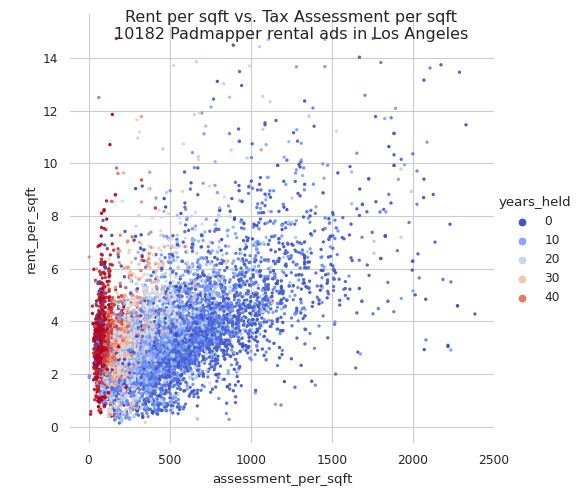
]]>Ryan Comptonryan@ryancompton.netProp 13 wtf2023-03-25T00:00:00+00:002023-03-25T00:00:00+00:00https://www.ryancompton.net/2023/03/25/prop13wtfI’ve decided to move my political blogging to a different site, https://prop13.wtf. Check it out! All kinds of cool stuff like tax assessments vs. rent in Los Angeles:
]]>Ryan Comptonryan@ryancompton.netEnable HTTPS for S3, Cloudfront, Namecheap2023-01-11T00:00:00+00:002023-01-11T00:00:00+00:00https://www.ryancompton.net/2023/01/11/httpsI finally got around to enabling https here. Some notes:
Namecheap sells ssl certs via PositiveSSL/Comodo. I thought this would be easiest but they don’t really work with AWS.
I’ll never get that $7 back
It’s more work to import a 3rd party certificate vs. creating one on AWS
After importing the 3rd party certificate (which has to happen in N. Virgina) AWS still claims that it’s not from a trusted source
]]>Ryan Comptonryan@ryancompton.netMigrating off s3_website.yml2023-01-10T00:00:00+00:002023-01-10T00:00:00+00:00https://www.ryancompton.net/2023/01/10/s3_websiteFirst post in 5+ years! I used to use s3_website to publish this blog. Turns out that project has been deprecated with nothing to replace it. Oh well.
Following this I’ve managed to setup Github Actions to build/deploy the blog. A few small changes:
Github stuff tends to default to main now but this repository is old and uses master
the [email protected] stuff in their blog post wasn’t working for me
Here’s the deploy script I’m using to publish this post:
name:Jekyll build and S3 deployon:push:branches:[master]# Allows you to run this workflow manually from the Actions tabworkflow_dispatch:env:AWS_ACCESS_KEY_ID:${{ secrets.AWS_ACCESS_KEY_ID }}AWS_SECRET_ACCESS_KEY:${{ secrets.AWS_SECRET_ACCESS_KEY }}AWS_DEFAULT_REGION:'us-west-2'jobs:build_and_deploy:runs-on:ubuntu-lateststeps:-uses:actions/checkout@v3-name:Set up Rubyuses:ruby/setup-ruby@359bebbc29cbe6c87da6bc9ea3bc930432750108with:ruby-version:'3.1'-name:Install dependenciesrun:bundle install-name:"BuildSite"run:bundle exec jekyll buildenv:JEKYLL_ENV:production-name:"DeploytoAWSS3"run:aws s3 sync ./_site/ s3://${{ secrets.AWS_S3_BUCKET_NAME }} --acl public-read --delete --cache-control max-age=604800-name:"CreateAWSCloudfrontInvalidation"run:aws cloudfront create-invalidation --distribution-id ${{ secrets.AWS_CLOUDFRONT_DISTRIBUTION_ID }} --paths "/*"
]]>Ryan Comptonryan@ryancompton.netOne thousand captcha photos organized with a neural network2017-08-18T00:00:00+00:002017-08-18T00:00:00+00:00https://www.ryancompton.net/2017/08/18/one-thousand-captcha-photos-organized-with-a-neural-networkCoauthored with Habib Talavati. Originally published on the Clarifai blog at https://blog.clarifai.com/one-thousand-captcha-photos-organized-with-a-neural-network-2/
The below image shows 1024 of the captcha photos used in “I’m not a human: Breaking the Google reCAPTCHA” by Sivakorn, Polakis, and Keromytis arranged on a 32x32 grid in such a way that visually-similar photos appear in close proximity to each other on the grid.
How did we do this?
To get from the collection of captcha photos to the grid above we take three steps: embedding via a neural net, further dimension reduction via t-SNE, and finally snapping things to a grid by solving an assignment problem.
Images are naturally very high-dimensional objects, even a “small” 224x224 image requires 2242243=150,528 RGB values. When represented naively as huge vectors of pixels visually-similar images may have enormous vector distances between them. For example, a left/right flip will generate a visually-similar image but can easily lead to a situation where each pixel in the flipped version has an entirely different value from the original.
Step 1: Reducing from 150528 to 1024 dimensions with a neural net
Our photos begin as 224x224x3 arrays of RGB values. We pass each image through an existing pre-trained neural network, Clarifai’s general embedding model which provides us with the activations from one of the top layers of the net. Using the higher layers from a neural net provides us with representations of our images which are rich in semantic information - the vectors of visually similar images will be close to each other in the 1024-dimensional space.
Step 2: Reducing from 1024 to 2 dimensions with t-SNE
In order to bring things down to a space where we can start plotting, we must reduce dimensions again. We have lots of options here. Some examples:
Inductive methods for embedding learning
Techniques such as the remarkably hard-to-Google Dr. LIM or Siamese Networks with triplet losses learn a function that can embed new images to fewer dimensions without any additional retraining. These techniques perform extremely well on benchmark datasets and are a great fit for online systems which must index previously-unseen images. For our application, we only need to get a fixed set of vectors reduced to 2D in one large, slow, step.
Transductive methods for dimensionality reduction
Rather than learning a function which can new points to few dimensions we can attack our problem more directly by learning a mapping from the high-dimensional space to 2D which preserves distances in the high-dimensional space as much as possible. Several techniques are available: t-SNE, and largeVis to name a few. Other methods, such as PCA, are not optimized for distance preservation or visualization and tend to produce less interesting plots. t-SNE, even during convergence, can produce very interesting plots (cf. this demonstration by @genekoganhere ).
We use t-SNE to map our 1024D vectors down to 2D and generate the first entry in the above grid. Recall that our high-dimensional space here are 1024D vector embeddings from a neural net, so proximal vectors show correspond to visually similar photos. Without the neural net t-SNE would be a poor choice as distances between the initial 224x224x3 vectors are uninteresting.
Step 3: Snapping to a grid with the Jonker-Volgenant algorithm
One problem with t-SNE’d embeddings is that if we displayed the images directly over their corresponding 2D points we’d be left with swaths of empty white space and crowded regions where images overlap each other. We remedey this by building a 32x32 grid and moving the t-SNE’d points to the grid in such a way that total distance traveled is optimal.
It turns out that this operation can be incredibly sophisticated. There is an entire field of mathematics, transportation theory, concerned with solutions to problems in optimal transport under various circumstances. For example, if one’s goal is to minimize the sum of the squares of all distances traveled rather than simply the sum of the distances traveled (ie the l2 Monge-Kantorovitch mass transfer problem) an optimal mapping can be found by recasting the assignment problem as one in computational fluid dynamics and solving the corresponding PDEs. Cedric Villani, who won a Fields medal in 2010, wrote a great book on optimal transportation theory which is worth taking a look at when you get tired of corporate machine learning blogs.
In our setting, we just want the t-SNE’d points to snap to the grid in a way that makes this look visually appealing and be as simple as possible. Thus, we search for a mapping that minimizes the sum of the distances traveled via a linear assignment problem. The textbook solution here is to use the Hungarian algorithm, however, this can be also be solved quite easily and much faster using Jonker-Volgenant and open source tools
How easy can we make this?
Pretty easy. In addition to the notebook listed above, we’ve also set up an API endpoint that will generate an image similar to the one above for an existing Clarifai application. Here we assume you already have created an application by visiting https://developer.clarifai.com/account/applications and added your favorite images to it by calling the resource
https://api.clarifai.com/v2/inputs. Then all you have to do is this:
Step 1: Kick off an asynchronous gridded t-SNE visualization
Since generating a visualization takes a while, we generate one asynchronously. We kick off a visualization by calling
POST https://api.clarifai.com/v2/visualizations/
You should get a response like below informing us a “pending” visualization is scheduled to be computed
Note the id ca69f34d53c742e1b4a1b71d7b4b4586. We will use that id to get the visualization we just kicked off.
Step 2: Check to see if the visualization is done
Call GET /v2/visualizations/ca69f34d53c742e1b4a1b71d7b4b4586. The returned visualization will be “pending” for a while, but eventually, we should get a response like this:
At last, the output.data.image.url contains your gridded t-SNE visualization.
]]>Ryan Comptonryan@ryancompton.netMy talk at the NYC Machine Learning meetup2016-12-06T00:00:00+00:002016-12-06T00:00:00+00:00https://www.ryancompton.net/2016/12/06/my-talk-at-the-nyc-machine-learning-meetupCheck out this video of my talk at the NYC Machine Learning meetup.
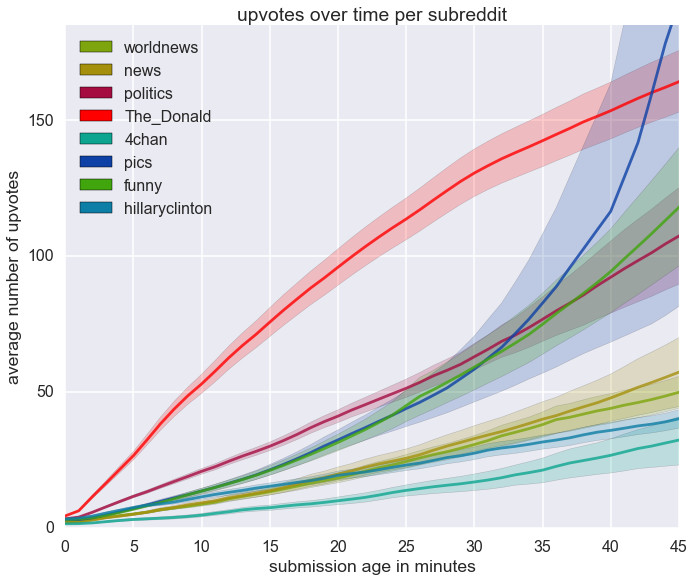
]]>Ryan Comptonryan@ryancompton.netUpvotes over time by subreddit or: Why /r/The_Donald is always on the front page2016-08-07T00:00:00+00:002016-08-07T00:00:00+00:00https://www.ryancompton.net/2016/08/07/upvotes-over-time-by-subreddit-or-why-the_donald-is-always-on-the-front-page-of-redditHere’s a plot of the cumulative number of upvotes per minute for submissions to a few major subreddits:
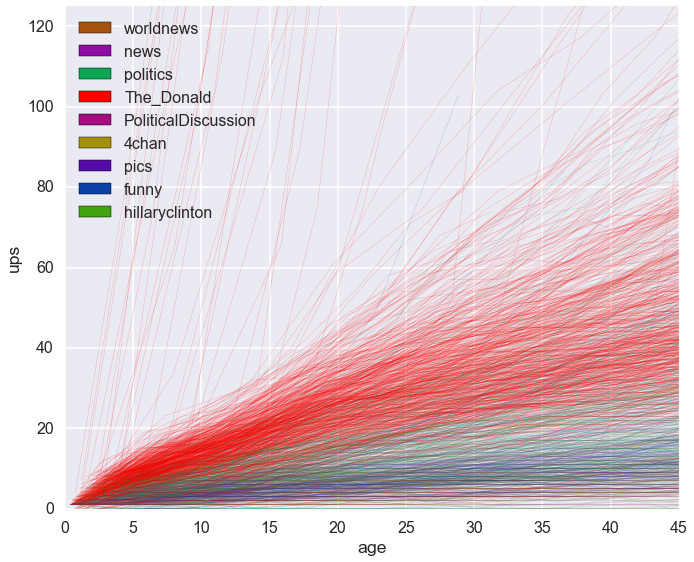
The data was collected by polling /new/ every 2 minutes for each subreddit over the past 3 days (2942138 records were found). The vast majority of submissions to reddit never get anywhere - I removed submissions which never attained over 50 upvotes which left me with 154160 records. The raw data is shown below:
Ranking on reddit is determined using a combination of upvotes, downvotes, and the age of the post at the time of each vote (cf. here, here, and here for some good explanations). In short, the ranking of a submission is set by the rating function
\[\begin{equation*}
f(n,t) = 45000\log_{10}(n) + t
\end{equation*}\]
where $n$ is the difference between upvotes and downvotes and $t$ is the number of seconds which elapsed between the post’s creation time and 7:46:43 am December 8th, 2005.
More recent posts have a larger $t$ which translates to a better ranking. Additionally, due to the shape of $\log_{10}$, votes matter substantially more when the number of upvotes nearly equals the number of downvotes (eg. when the post is brand new). Thus, the best way to get your post to the front page is to upvote aggressively when the post is very young.
My data suggests that members of /r/The_Donald are aware of this which explains why their new submissions have so many more upvotes despite the fact that competing subreddits in the plot are several orders of magnitude larger.
]]>Ryan Comptonryan@ryancompton.netTaxi Strava2016-06-11T00:00:00+00:002016-06-11T00:00:00+00:00https://www.ryancompton.net/2016/06/11/taxi-stravaLast year Chris Whong used a foil request to obtain a dataset with information on the locations, times, and medallions for 173 million NYC cab rides. I’m interested is determining which cabs are the fastest cabs are and how quickly they can get between various parts of the city.
Data
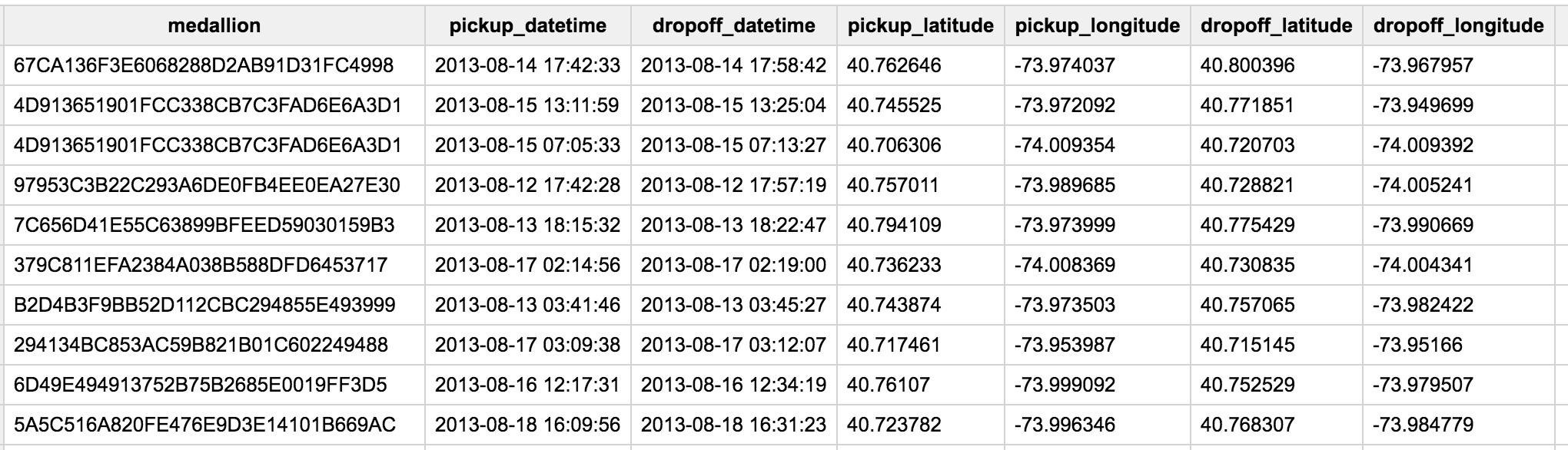
Reddit users imjasonh and fhoffa parsed the raw data and loaded it into a public BigQuery table (another version is also available from the NYC Taxi and Limousine Commission) The schema looks like:
As you can see, each ride has very specific details on pickup/dropoff locations as well as start/end times. I am interested in answering questions along the lines of “How fast do cabs get to the Flatiron from the Upper East Side?” which is hard to do from precise latitudes and longitudes. To rectify this I took a 6-character geohash of every pickup and dropoff location. A 6-character geohash buckets together coordinates that are within 0.61km of each other which allowed me to easily aggregate popular routes. An example is shown below (image from movable-type):
To make things more human readable, I used the geonames api to map the center of each bucket to an intersection. Not every geohash could be mapped to an intersection this way and those trips were dropped. Data was further cleaned by dropping trips using (hack_license != "0") AND (hack_license != "CFCD208495D565EF66E7DFF9F98764DA") which was observed in a discussion about the dataset.
This leaves us with a dataset of 158,320,608 cab rides bucketed into 32,654 distinct start/end points.
Results
Note: The 999th quantile for a trip’s average speed is 49.4289 mph - one trip had an average speed of 236,986,708 mph (roughly one third the speed of light). I removed any trip with average speed over 60mph from the data.
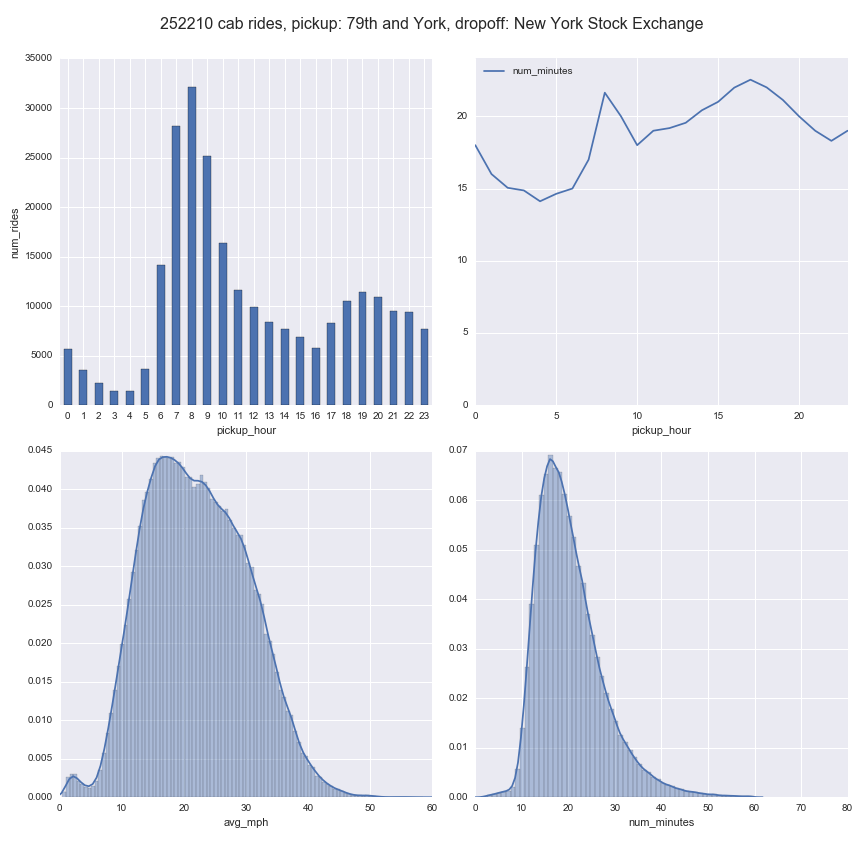
It takes ~20 minutes to get from 79th and York to the NYSE
I found 252,210 trips along this route in my data. On average cabs take 20.35 minutes and move at 22.11 mph. Of course you’ll go faster at 4am but most people don’t start their commute until 6 or 7am:
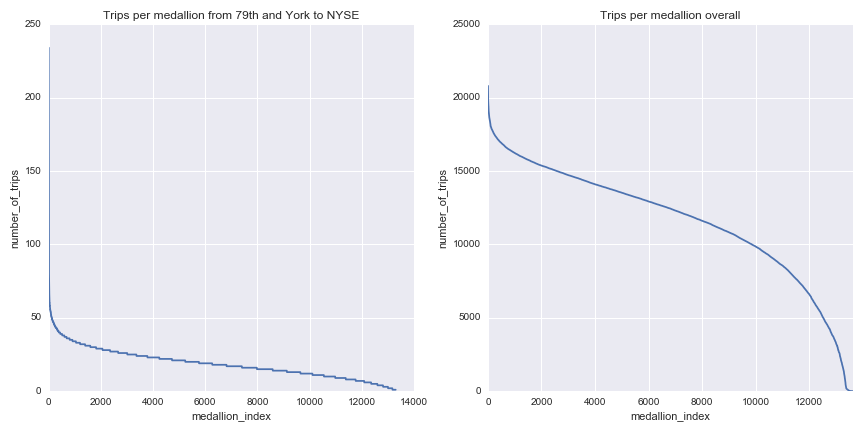
Of the 13,347 medallions only a few regularly make the trip from 79th and York to Wall Street. The most dedicated cab drove the route 234 times over the year (only 7 drove it over 100 times):
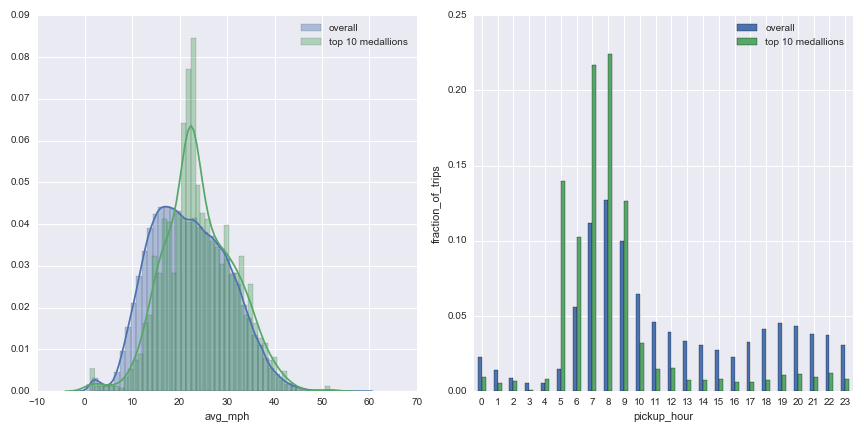
The top 10 most frequent cab share drivers don’t go any faster than most though their average speed is more predictable (probably due to the fact that they often drive at the same time each day).
Additionally, when one uses the morning cab share they are far more likely to be picked up by a usual (especially at 5am):
]]>Ryan Comptonryan@ryancompton.netWhat convolutional neural networks look at when they look at nudity2016-04-19T00:00:00+00:002016-04-19T00:00:00+00:00https://www.ryancompton.net/2016/04/19/what-convolutional-neural-networks-look-at-when-they-look-at-nudityOriginally published on the Clarifai blog at http://blog.clarifai.com/what-convolutional-neural-networks-see-at-when-they-see-nudity/
Last week at Clarifai we formallyannounced our Not Safe for Work (NSFW) adult content recognition model. Automating the discovery of nude pictures has been a central problem in computer vision for over two decades now and, because of it’s rich history and straightforward goal, serves as a great example of how the field has evolved. In this blog post, I’ll use the problem of nudity detection to illustrate how training modern convolutional neural networks (convnets) differs from research done in the past.
(Warning & Disclaimer: This post contains visualizations of nudity for scientific purposes. Read no further if you are under the age of 18 or if you are offended by nudity.)
1996
A seminal work in this field is the aptly-named “Finding Naked People” by Fleck et at.. It was published in the mid 90s and provides a good example of the kind of work that computer vision researchers would do prior to the convnet takeover. In section 2 of the paper the summarize the technique:
The algorithm:
first locates images containing large areas of skin-colored region;
then, within these areas, finds elongated regions and groups them into possible human limbs and connected groups of limbs, using specialized groupers which incorporate substantial amounts of information about object structure
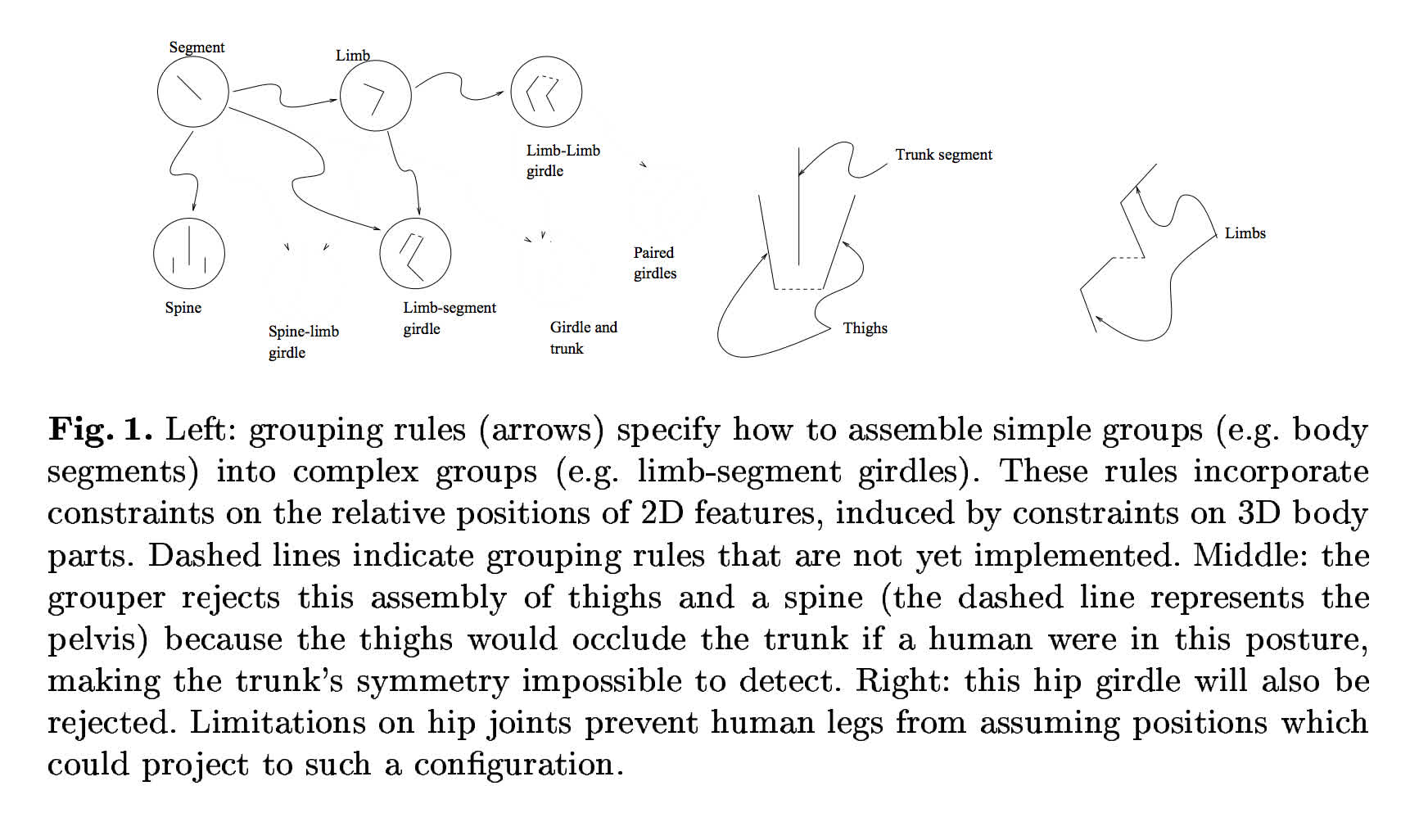
Skin-detection is done by filtering in color space (note: HSV usually works well here but this paper implemented a specialized transformation of RGB) and grouping skin regions is done by modeling the the human figure “as an assembly of nearly cylindrical parts, where both the individual geometry of the parts and the relationships between parts are constrained by the geometry of the skeleton” (cf. section 2). To get a better idea of the engineering that goes into building an algorithm like this we turn to fig. 1 in the paper where the authors illustrate a few of their handbuilt grouping rules:
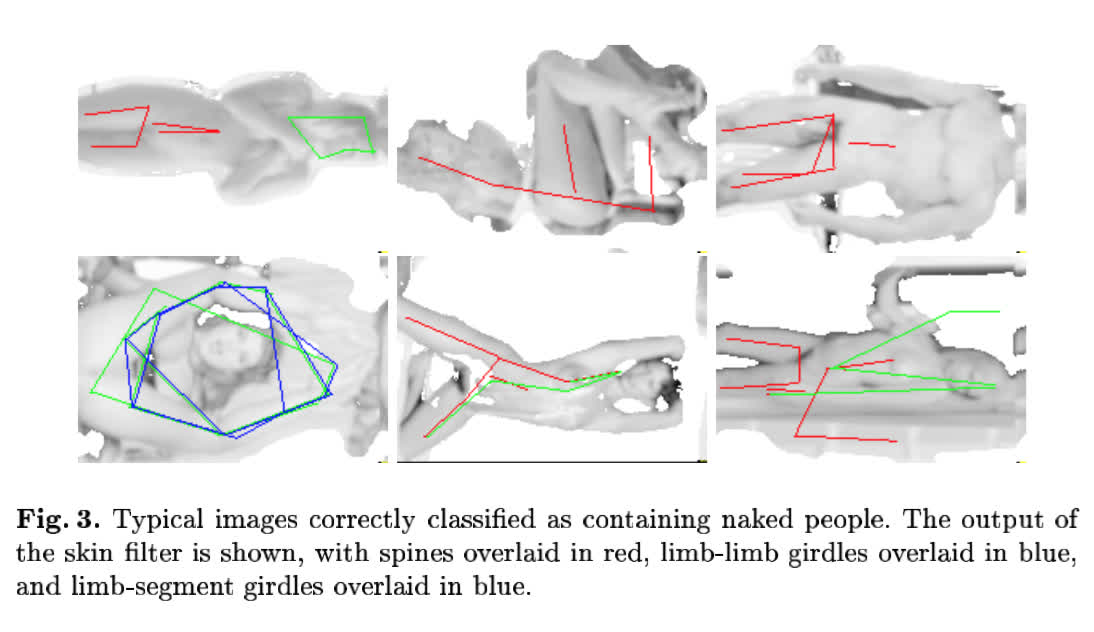
The paper reports “60% precision and 52% recall on a test set of 138 uncontrolled images of naked people”. They also provide examples of true positives and false positives with visualizations of the features discovered by the algorithm overlaid:
A major issue with building features by hand is that their complexity is limited by the patience and imagination of the researchers. In the next section, we’ll see how a convnet trained to perform the same task can learn much more sophisticated representations of the same data.
2014
Instead of devising formal rules to describe how the input data should be represented, deep learning researchers devise network architectures and datasets which enable an A.I. system to learn representations directly from the data. However, since deep learning researchers don’t specify exactly how the network should behave on a given input, a new problem arises: How can one understand what the convolutional networks are activating on?
Understanding the operation of a convnet requires interpreting the feature activity in various layers. In the rest of this post we’ll examine an early version of our NSFW model by mapping activities from the top layer back down to the input pixel space. This will allow us to see what input pattern originally caused a given activation in the feature maps (ie. why an image was flagged as “NSFW”).
Occulsion Sensitivity
The image at the top of the post shows photos of LenaSöderberg after 64x64 sliding windows with a stride of 3 have applied of our nsfw model to cropped/occuluded versions of the raw image.
To build the heatmap on the left we send each window to our convnet and average the “NSFW” scores over each pixel. When the convnet sees a crop filled with skin it tends to predict “NSFW” which leads to large red regions over Lena’s body. To create the heatmap on the right we systematically occlude parts of the raw image and report 1 minus the average “NSFW” scores (i.e. the “SFW” score). When the most NSFW regions are occluded the “SFW” scores increase and we see higher values in the heatmap. To be clear, the below figures have examples of what kind of images were fed into the convnet for each of two experiments above:
One of the nice things about these occlusion experiments is that they’re possible to perform when the classifier is a complete black box. Here’s a code snippet that reproduces these results via our API:
# NSFW occulsion experiment
fromStringIOimportStringIOimportmatplotlib.pyplotaspltimportnumpyasnpfromPILimportImage,ImageDrawimportrequestsimportscipy.sparseasspfromclarifai.clientimportClarifaiApiCLARIFAI_APP_ID='...'CLARIFAI_APP_SECRET='...'clarifai=ClarifaiApi(app_id=CLARIFAI_APP_ID,app_secret=CLARIFAI_APP_SECRET,base_url='https://api.clarifai.com')defbatch_request(imgs,bboxes):"""use the API to tag a batch of occulded images"""assertlen(bboxes)<128#convert to image bytes
stringios=[]forimginimgs:stringio=StringIO()img.save(stringio,format='JPEG')stringios.append(stringio)#call api and parse response
output=[]response=clarifai.tag_images(stringios,model='nsfw-v1.0')forresult,bboxinzip(response['results'],bboxes):nsfw_idx=result['result']['tag']['classes'].index("sfw")nsfw_score=result['result']['tag']['probs'][nsfw_idx]output.append((nsfw_score,bbox))returnoutputdefbuild_bboxes(img,boxsize=72,stride=25):"""Generate all the bboxes used in the experiment"""width=boxsizeheight=boxsizebboxes=[]fortopinrange(0,img.size[1],stride):forleftinrange(0,img.size[0],stride):bboxes.append((left,top,left+width,top+height))returnbboxesdefdraw_occulsions(img,bboxes):"""Overlay bboxes on the test image"""images=[]forbboxinbboxes:img2=img.copy()draw=ImageDraw.Draw(img2)draw.rectangle(bbox,fill=True)images.append(img2)returnimagesdefalpha_composite(img,heatmap):"""Blend a PIL image and a numpy array corresponding to a heatmap in a nice way"""ifimg.mode=='RBG':img.putalpha(100)cmap=plt.get_cmap('jet')rgba_img=cmap(heatmap)rgba_img[:,:,:][:]=0.7#alpha overlay
rgba_img=Image.fromarray(np.uint8(cmap(heatmap)*255))returnImage.blend(img,rgba_img,0.8)defget_nsfw_occlude_mask(img,boxsize=64,stride=25):"""generate bboxes and occluded images, call the API, blend the results together"""bboxes=build_bboxes(img,boxsize=boxsize,stride=stride)print'api calls needed:{}'.format(len(bboxes))scored_bboxes=[]batch_size=125foriinrange(0,len(bboxes),batch_size):bbox_batch=bboxes[i:i+batch_size]occluded_images=draw_occulsions(img,bbox_batch)results=batch_request(occluded_images,bbox_batch)scored_bboxes.extend(results)heatmap=np.zeros(img.size)sparse_masks=[]foridx,(nsfw_score,bbox)inenumerate(scored_bboxes):mask=np.zeros(img.size)mask[bbox[0]:bbox[2],bbox[1]:bbox[3]]=nsfw_scoreAsp=sp.csr_matrix(mask)sparse_masks.append(Asp)heatmap=heatmap+(mask-heatmap)/(idx+1)returnalpha_composite(img,80*np.transpose(heatmap)),np.stack(sparse_masks)#Download full Lena image
r=requests.get('https://clarifai-img.s3.amazonaws.com/blog/len_full.jpeg')stringio=StringIO(r.content)img=Image.open(stringio,'r')img.putalpha(1000)#set boxsize and stride (warning! a low stride will lead to thousands of API calls)
boxsize=64stride=48blended,masks=get_nsfw_occlude_mask(img,boxsize=boxsize,stride=stride)#viz
blended.show()
While these kinds of experiments provide a straightforward way of displaying classifier outputs they have a drawback in that the visualizations produced are often quite blurry. This prevents us from gaining meaningful insight into what the network is actually doing and understanding what could have gone wrong during training.
Deconvolutional Networks
Once we’ve trained a network on a given dataset we’d like to be able to take an image and a class and ask the convnet something along the lines of “How can we change this image in order to look more like the given class?”. For this we use a deconvolutional network (deconvnet), cf section 2 from Zeiler and Fergus 2014:
A deconvnet can be thought of as a convnet model that uses the same components (filtering, pooling) but in reverse, so instead of mapping pixels to features does the opposite. To examine a given convnet activation, we set all other activations in
the layer to zero and pass the feature maps as input to the attached deconvnet layer. Then we successively (i) unpool, (ii) rectify and (iii) filter to reconstruct the activity in the layer beneath that gave rise to the chosen activation. This is
then repeated until input pixel space is reached.
The procedure is similar to backpropping a single strong activation (rather than the usual gradients), i.e. computing $\frac{\partial h}{ \partial X_n}$ where $h$ is the element of the feature map with the strong activation and $X_n$ is the input image.
Here is the result we get when using a deconvnet to visualize how we should modify photos of Lena to look more like pornography (note: the deconvnet used here needed a square image to function correctly - we padded the full Lena image to get the right aspect ratio):
Barbara is the G-rated version of Lena. According to our deconvnet, we could modify Barbara to look more PG by adding redness to her lips:
This image of Ursula Andress as Honey Rider in the James Bond film Dr. No was voted number one in “the 100 Greatest Sexy Moments in screen history” by a UK survey in 2003:
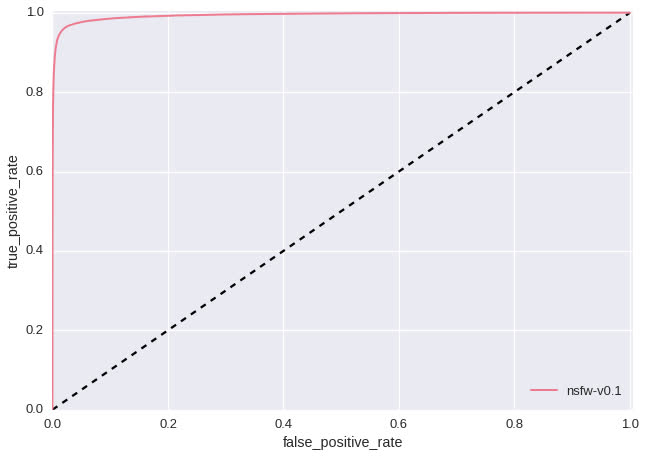
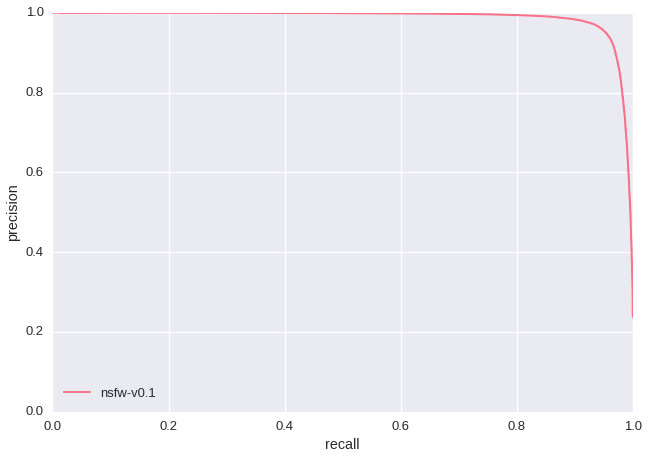
A salient feature of the above experiments is that the convnet learned red lips and navels as indicative of “NSFW”. This likely means that we didn’t include enough images of red lips and navels in our “SFW” training data. Had we only evaluated our model by examining precision/recall and ROC curves (shown below - test set size: 428,271) we would have never discovered this issue as our test data would have the same shortcoming. This highlights a fundamental difference between training rule-based classifiers and modern A.I. research. Rather than redesigning features by hand, we redesign our training data until the discovered features are improved.
Finally, as a sanity check, we run the deconvnet on hardcore porno to ensure that the learned feature activations do indeed to correspond to obviously nsfw objects:
Here, we can clearly see that the convnet correctly learned penis, anus, vulva, nipple, and buttocks - objects which our model should flag. What’s more, the discovered features are far more detailed and complex than what researchers could design by hand which helps explain the major improvements we get by using convnets to recognize NSFW images.
]]>Ryan Comptonryan@ryancompton.netDarknet Market Basket Analysis2015-03-24T00:00:00+00:002015-03-24T00:00:00+00:00https://www.ryancompton.net/2015/03/24/darknet-market-basket-analysisThe Evolution darknet marketplace was an online black market which operated from January 2014 until Wednesday of last week when it suddenly disappeared. A few days later, in a reddit post, gwern released a torrent containing daily wget crawls of the site dating back to its inception. I ran some off-the-shelf affinity analysis on the dataset – here’s what I found:
Products can be categorized based on who sells them
On Evolution there are a few top-level categories (“Drugs”, “Digital Goods”, “Fraud Related” etc.) which are subdivided into product-specific pages. Each page contains several listings by various vendors.
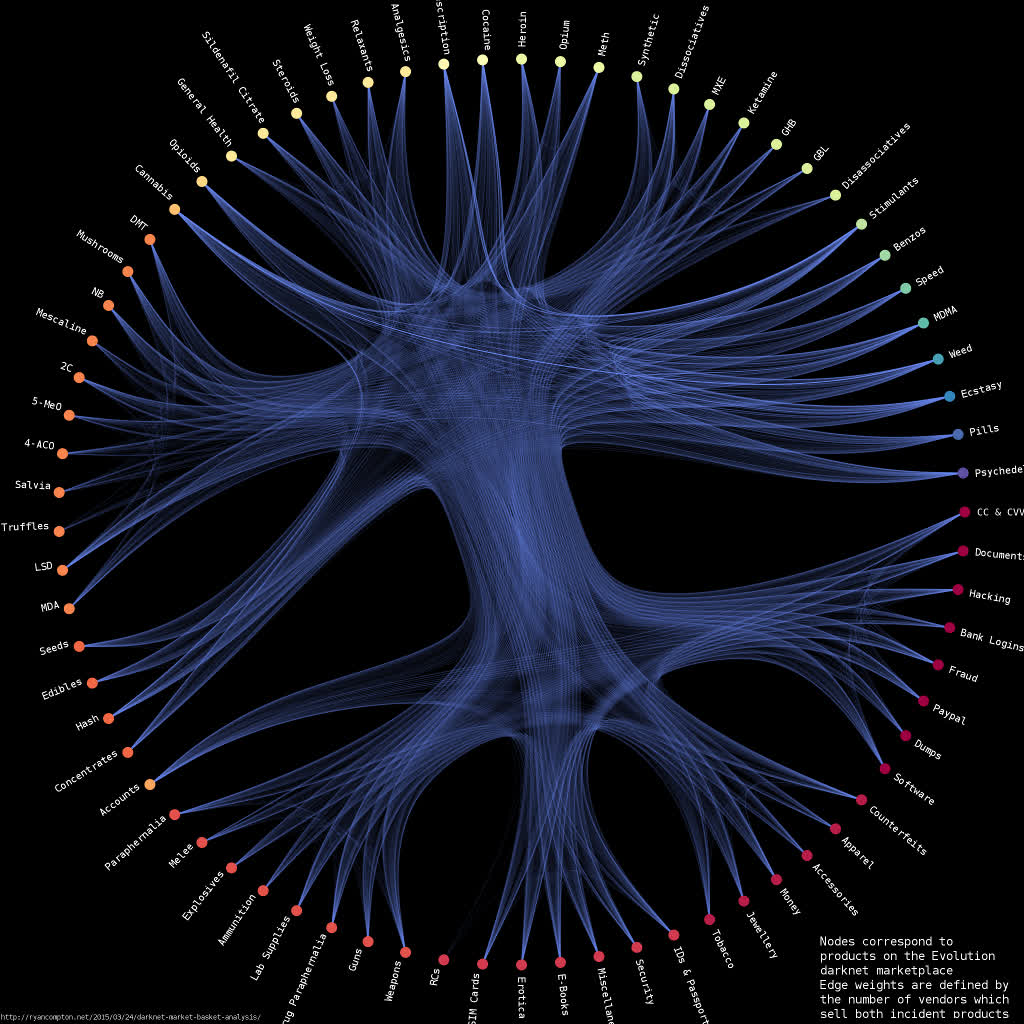
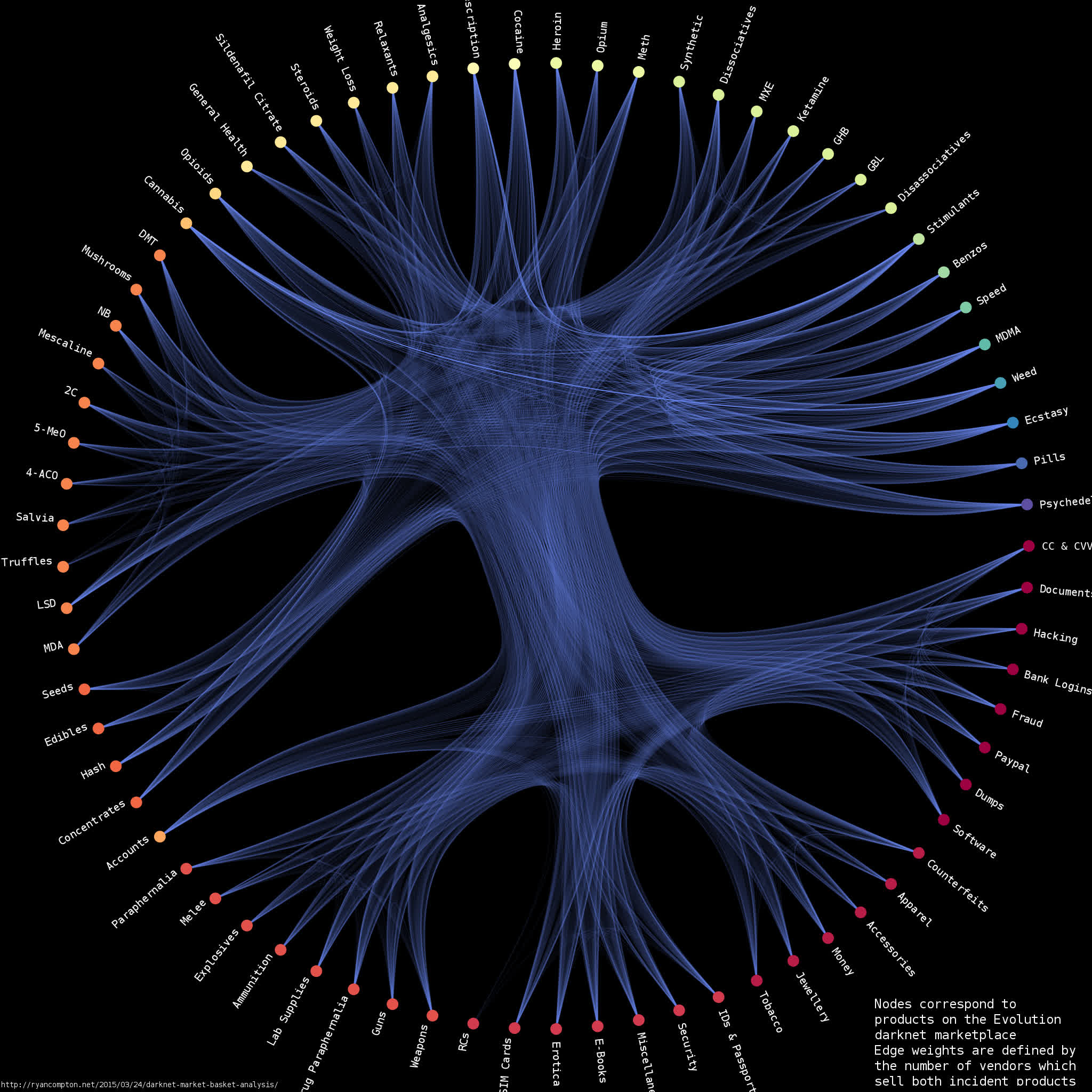
I built a graph between products based on vendor co-occurrence relationships, i.e. each node corresponds to a product with edge weights defined by the number of vendors who sell both incident products. So, for example, if there are 3 vendors selling both mescaline and 4-AcO-DMT then my graph has an edge with weight 3 between the mescaline and 4-AcO-DMT nodes. I used graph-tool’s implementation of stochastic block model-based hierarchal edge bundling to generate the below visualization of the Evolution product network:
The graph is available in graphml format here. It contains 73 nodes and 2,219 edges (I found a total of 3,785 vendors in the data).
Edges with higher weights are drawn more brightly. Nodes are clustered with a stochastic block model and nodes within the same cluster are assigned the same color. There is a clear division between the clusters on the top half of the graph (correpsonding to drugs) and the clusters on the bottom half (corresponding to non-drugs, i.e. weapons/hacking/credit cards/etc.). This suggests that vendors who sold drugs were not as likely to sell non-drugs and vice versa.
I used a short python script to parse the scraped html and remove duplicate data, its available here. It takes a while to go through the entire dataset (which is about 90GB); if you’d like to skip that you can download the results of my parse as a .tsv file. The plotting code is available as an ipython notebook. High-res version of the above plot here.
91.7% of vendors who sold speed and MDMA also sold ecstasy
Association rule learning is a straightforward and popular way to solve problems in market basket analysis. The traditional application is to suggest items to shoppers based on what other customers are putting in their carts. For some reason the canonical example is “customers who buy diapers also buy beer”.
We don’t have customer data from a crawl of the public postings on Evolution. However, we do have data on what each vendor sells which can help us quantify results suggested by the visual analysis done above.
Here’s an example of what our database looks like (the complete file has 3,785 rows (one for each vendor)):
Before saying anything more about association rule learning here’s a quick glossary of terms:
The support, $supp(X)$, of an itemset, $X$, is defined as the proportion of transactions in the data set which contain $X$. In the table above, the support of ‘Cocaine’ is 2 because it appears in two vendors’ storefronts (MrHolland and Spinifex)
The confidence of a rule is defined $\mathrm{conf}(X \Rightarrow Y) = \mathrm{supp}(X \cup Y) / \mathrm{supp}(X)$. In our example the confidence of the rule ‘Cannabis’ ==> ‘Cocaine’ is 2/3 because out the 3 vendors who sell ‘Cannabis’ 2 of them sell ‘Cocaine’. The support of this rule is 2.
Association rule mining is a huge field within computer science – hundreds (thousands?) of papers have been published over the past two decades. The necessary algorithms are very complex but open source implementations are available. My favorite collection (and the one I used for these experiments) is Philippe Fournier Viger’s spmf.
I ran the FP-Growth algorithm with a minimum allowable support of 40 and a minimum allowable confidence of 0.1. The algorithm learned 12,364 rules. These can be downloaded as a .tsv here. I’ve selected a few rules for display below:
antecedent
consequent
support
confidence
[‘Speed’, ‘MDMA’]
[‘Ecstasy’]
155
0.91716
[‘Ecstasy’, ‘Stimulants’]
[‘MDMA’]
310
0.768
[‘Speed’, ‘Weed’, ‘Stimulants’]
[‘Cannabis’, ‘Ecstasy’]
68
0.623
[‘Fraud’, ‘Hacking’]
[‘Accounts’]
53
0.623
[‘Fraud’, ‘CC & CVV’, ‘Accounts’]
[‘Paypal’]
43
0.492
[‘Documents & Data’]
[‘Accounts’]
139
0.492
[‘Guns’]
[‘Weapons’]
72
0.98
[‘Weapons’]
[‘Guns’]
72
0.40
Other Remarks
I think I’ve only scratched the surface of what’s possible with this data. There are much more detailed product descriptions for each listing in the .tsv. That text is harder to work with so it will take some time to figure out what makes sense.

















{kind=link}